近期在做从oracle到HBase的数据库迁移,接触到了ORM以及如何设计HBase的schema,下面把这几天的学习成果记录下来。
schema设计
schema我的理解就是把逻辑上的数据模型和物理上的存储实现结合起来。考虑到nosql最大的特点在于横向扩展方便,结合HBase按列存储的特点(同一个column family,CF)存储在同一个文件中,它的schema(schema用词可能不准,因为它是schemaless的)设计主要考虑如何扩展方便、如何减少存储/查询开销。一般有如下三条设计原则Denormalization、Duplication和Intelligent Keys。
反序列化和复用
相对于sql是把大表细分为小表,再通过join操作来合并成大表;nosql往往是通过数据冗余把小表写大,两个实体共用同一个实现,也就是增加一些字段从而避免join问题,因为nosql存储廉价。其实join实质就是把多张小表合并成一张大表,对应mongo就是嵌套,对应HBase/cassandra就是把小表用更多的字段写大然后用row key连接起来。当数据量大的时候不join比join好是指合并的代价大于存储的代价,所以nosql通过反序列化刚好不用join才得以体现优势。hbasecon2012上有一篇HBase Schema Design(how i learned to stop worrying and love denormalization)详细介绍了denormalization。
rowkey设计
因为HBase中数据是根据rowkey索引的,相近的rowkey(默认是字典序)在同一个regionserver上,rowkey设计主要考虑把同时使用的数据存放在一起,减少查询开销,这是根据业务需求定的。比如利用时间戳做rowkey的一部分(把MAX_VALUE-timestamp加到rowkey的最后)可以查询到最近使用的,再比如如下这个例子把关系型数据库中的两张表的主键合在一起。
一个订单例子的转变如下: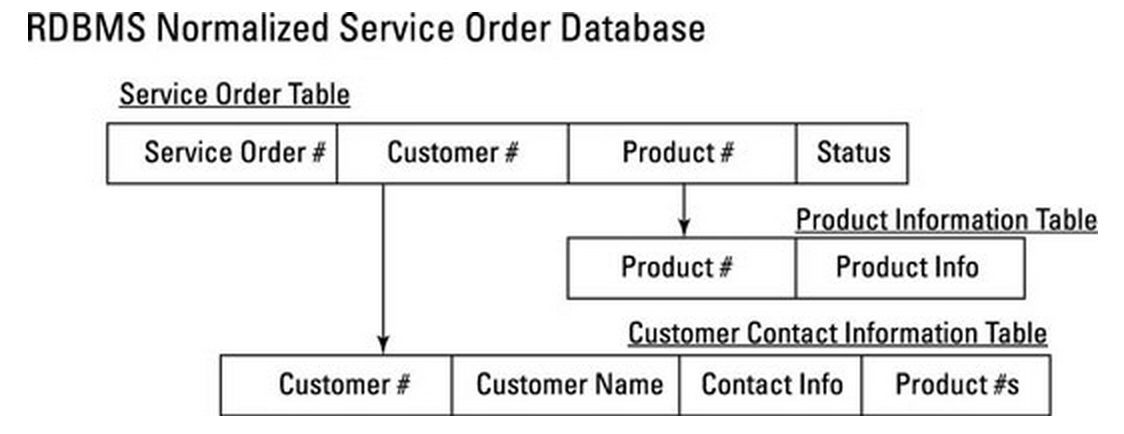
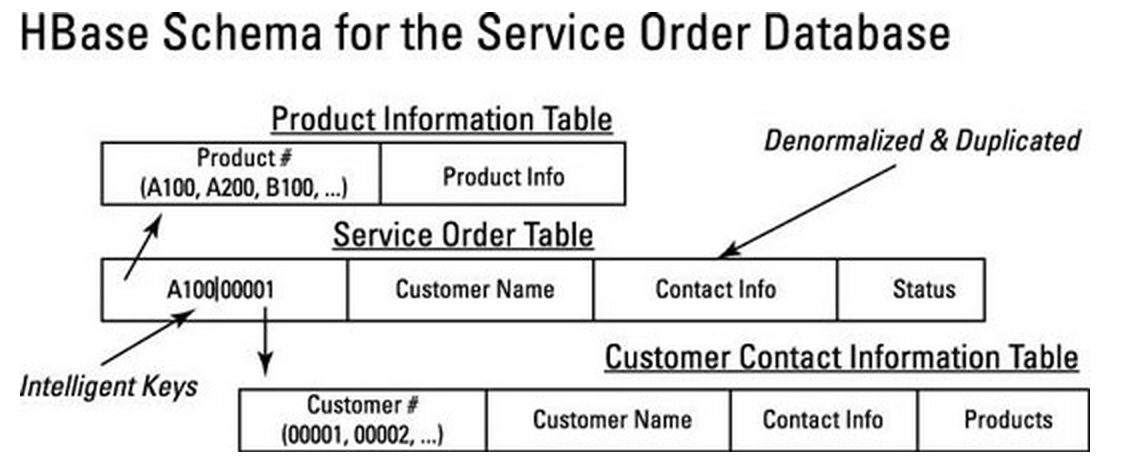
从上面这个例子可以看出,在rdbms中,通常是通过service order table根据customer和product来left join这两张表进行查询;而在HBase中,对于service order这张表如果查询customer就没必要做join了,之前通过外键索引到customer信息,在这里已经保存在service order里了。这虽然会带来额外的存储,但在nosql中这是很正常的操作方式。
此外,这个rowkey的设计既能找到对应的product和customer,并且把所有A开头的商品保存在了一起,如果查询经常是某一类商品一起查询的话,那这种设计方式就很合理。
转换例子
一般来说HBase schema的设计主要考虑这三点,再看两个根据这三条原则对应到数据转换例子。
一对多
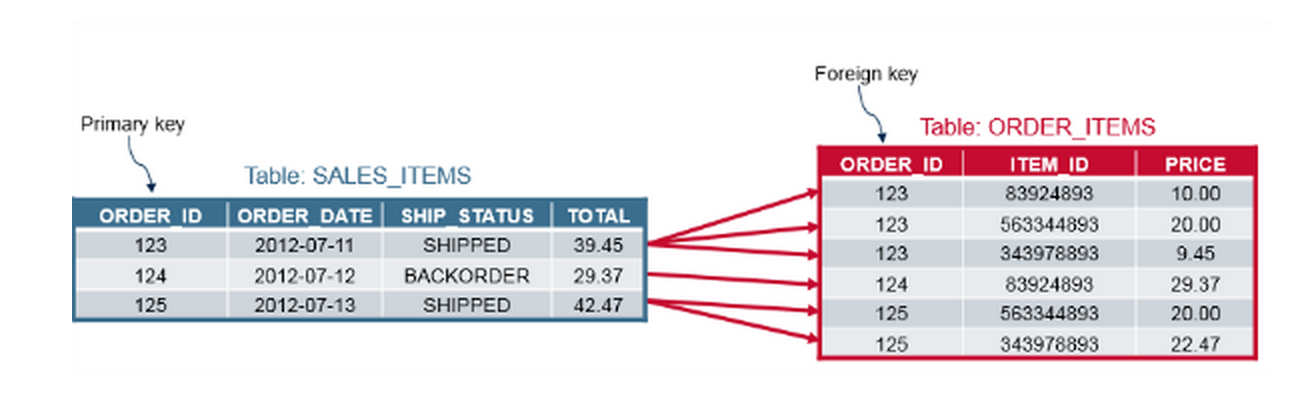
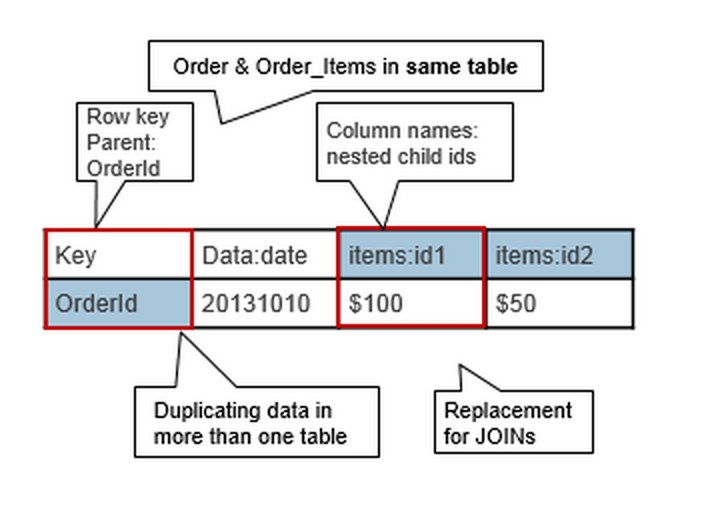
多对多
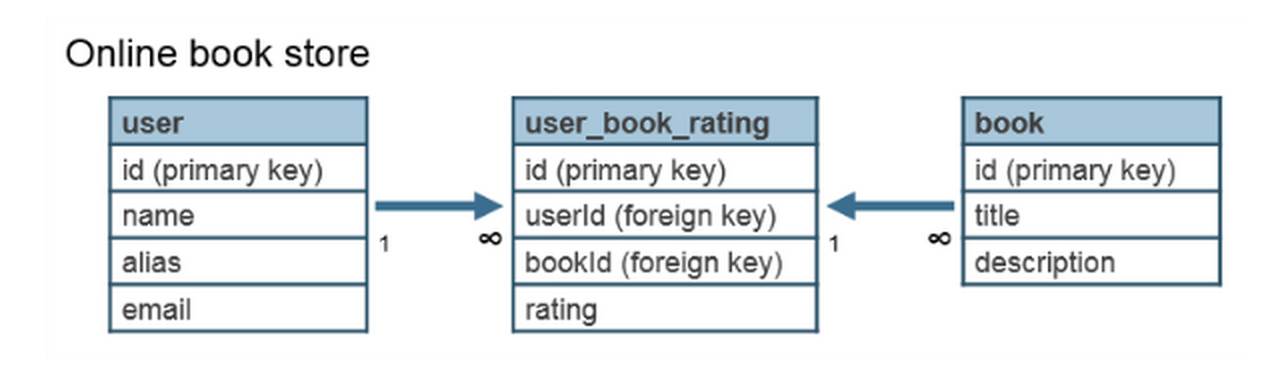
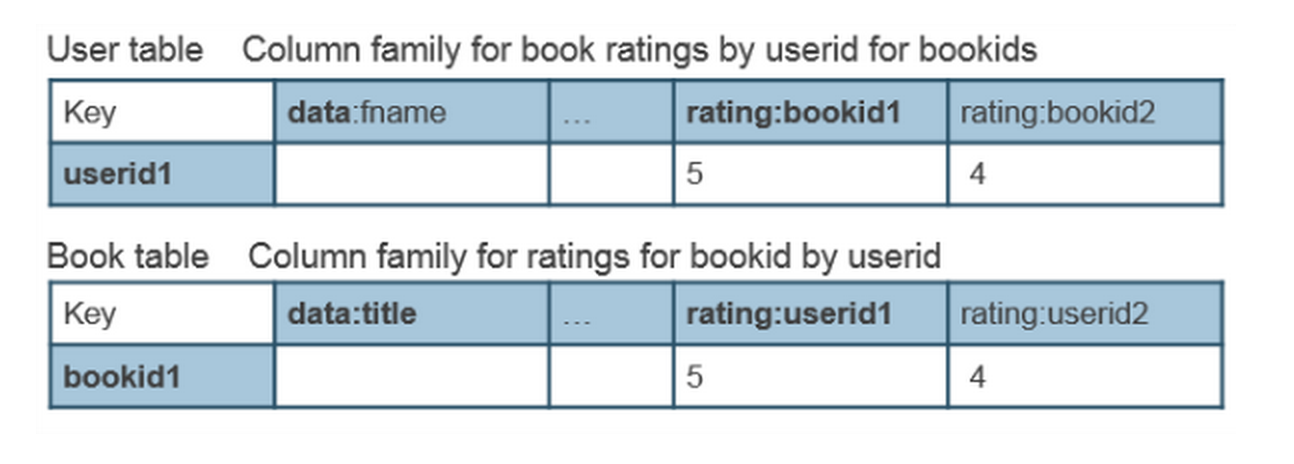
第二个多对多的例子就是把两个一对多结合起来,没有借助一张中间表,这是因为HBase的CF是可以随意添加column的,很灵活,所以刚好可以这么做。
关于看的两篇论文
我感觉这两篇论文侧重于两个方向,这在最后的问题中会说明,然后基本也是guide。
论文 MySQL to NoSQL Data Modeling Challenges in Supporting Scalability主要写了如何迁移tweet(重点在第6段),主要也是schema变化的描述,基本思想就是上面三点。
另一篇 ONDM: an Object-NoSQL Datastore Mapper 介绍了一个ORM映射框架ORM,现在ORM框架已经很多了,这个和现在的也差不多,下面介绍一下ORM。
ORM
ORM(Object Relational Mapping)通常是指对象和关系型数据的映射,对应在nosql中也叫ODM(D:data),OGM(G:grid)。这个东西可以让程序员不用关心数据库的设计,而只用关系对象之间的关系。我主要是了解了一些针对nosql的ORM框架,比如hibernate ogm,kundera,datanucleus。
从上层来看他们大都是一样的,都是把对象(java中的class)通过注解的方式映射到nosql中,最简单的数据模型包括实体、属性和关系。比如这样:
这些@符号就把该类中的属性映射到HBase中了,至于数据库连接和class与CF的映射通常是通过xml文件来描述。
思考
1、根据先有对象的逻辑,再设计HBase,其实考虑的就是业务需求,把哪些字段放在一起,rowkey怎么设计,哪些需要join合并起来等等。
2、迁移数据的话肯定是设计好schema然后抽数据(不会通过两次ORM来迁移),ORM只是说在开发过程中层次分离,偏向于数据库开发,而不是数据库迁移。
所以感觉这两个不是同一个东西= =||