某公司的某关系型数据库中有79张表,数据量从几千条到上亿条不等,其中最大的交易流水表每月大约增量1亿2千万条数据。每张表都有自己的主键,但是表与表之间没有明确的关系,表之间的关系由业务和应用来驱动。目前对这些表主要的操作是进行校验然后生成报文,比如查询出某张表某个字段不符合规范的记录,然后对其修改。整个过程分为四个部分,导入数据,校验,补录,导出生成报文;对应于数据库的四种操作,导入,查询,更新,导出。这套流程在传统关系型数据库中进行时,因为数据量较大,在校验和补录阶段比较缓慢,而对其做分库分表又比较麻烦,另外后续需要对这些数据进行挖掘和分析,考虑到大数据平台在对数据统一管理和数据分析方面的优越性,因此想将整个流程迁入大数据平台。
故事一
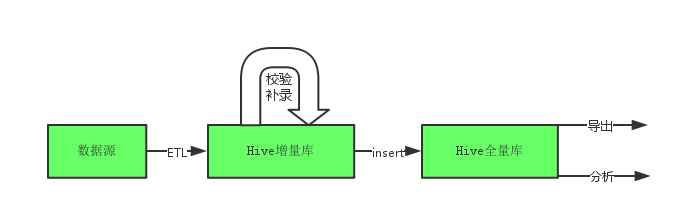
因为现在Hadoop已经成为大数据平台的标准,所以以Hadoop为基础构建整个系统。首先想到的是利用Hadoop+Hive的结构来完成整套流程,Hadoop提供存储(HDFS)和调度框架(YARN)以及计算引擎(MapReduce),Hive本身可以建表,它的语法HQL和SQL非常相似,可以用来替代之前的关系型数据库。之后的数据分析可以在Hive上进行(基于表做分析)也可以在HDFS上进行(基于文件做分析)。从上图中可以看到,整个系统的流程就是先把原始数据以文本形式或者从关系型数据库导入到大数据平台中,之后需要对这部分数据进行校验、补录和分析。下面重点考虑导入、校验、补录三个部分。
简单分析导入、校验、补录三个部分。导入数据基本思路可以通过Sqoop从关系型数据库导入Hadoop平台,Sqoop是Hadoop提供的一款ETL工具,它能够把关系型数据库中的数据迁入Hadoop的数据仓库中;也可以通过Hive的import工具从文本文件导入。校验也是一种查询,我们可以把一些校验规则封装成一些函数,这可以通过Hive的UDF来实现,然后就可以通过SQL的方式来调用这些校验函数。另外校验只需要校验失败的数据,对于原始正确的数据不必重复校验,所以应该把数据分成全量数据库和增量数据库,只需要在增量库校验即可,把校验通过的数据导入进全量数据库,然后全量数据库进行数据的分析。最后生成报文是生成全量报文,包括原始正确的数据和校验之后正确的数据,所以要能够更新错误的数据并且能够获得全量数据。
从上面的分析中可以看出,在校验之后通常需要对不合格数据进行补录,也就是需要update增量数据库,但是众所周知Hive原生是不支持update操作的,因此为了能够更新数据,需要引入Hive的acid特性,Hive在0.14版本之后加入了这一功能。但是Hive的acid特性只能针对ORC格式的表并且需要对表进行分桶得到若干个bucket,然后才能启用事务的支持,具体做法参见Hive Transactions。虽然通过这一系列操作可以让Hive的HQL支持update和delete语法,但是这种更新表中数据的方式是启动一个MapReduce任务并且需要做全表扫描,效率低下,即使可以通过加上分区字段和分桶的字段来提高效率,但是仍然比较慢,并且Hive做acid一直没有很好的实际案例。此外这种方法需要文件格式为ORC格式,目前Impala不能查询ORC格式的表,要想使用Impala做交互式查询必须再建一套Impala支持的表,比如text或者parquet格式的表,这样数据冗余太大,浪费硬盘空间。另外bucket对tez的使用也有影响,主要表现为tez无法很好的对划分成bucket的表进行分块,这样在执行MapReduce运算时,只能得到1个mapper,效率太低。
这种方法的一个替代,是通过一张增量表和一张基表以及一个全量视图来获取所有的最新数据,然后通过insert override基表来达到增量式更新。这种方法虽然不必使用ORC和启用事务,但是也面临更改缓慢的问题。
总结一下利用Hadoop+Hive方案的优缺点。优点是导入文本数据非常迅速,因为Hive在导入数据时只需要指定文件的分隔符,并不关心表结构与文件结构的关系,只有在查询时才判断数据是否合法,因此导入过程十分迅速,同时Hive支持的SQL语法比较全面,ORC格式配合MapReduce进行查询也比较快速,对于一个月的交易流水表可以在100秒左右根据任意过滤要求查询到相应的数据。但是这种架构的缺点也是显而易见的,主要是数据修改的问题,经过测试,在一个月的交易流水增量表中update一条记录需要大约60秒的时间,这是不能接受的。分析可以发现,其实整个流程包括OLTP和OLAP两个部分,Hive本身是个OLAP的系统,用它来处理OLTP部分是不合适的。至于OLTP部分可以用关系型数据库完成也可以用HBase来完成,考虑到Hadoop平台的统一性,这里用Hadoop家族的数据库HBase来处理OLTP。
故事二
经过讨论,我们认为update和delete这种操作不适合在Hive层面上执行,因为Hadoop本身是一个append-only的系统,Hive默认是直接建立在HDFS之上的,适合作为全部历史的数据仓库保存全量数据和进行分析查询,因此想到了Hadoop家族的数据库HBase。用HBase有两个好处:
- HBase可以update数据,只需要获得错误数据的rowkey即可,并且这个过程非常快。这是因为HBase根据rowkey做全局唯一索引,可以在毫秒级定位某条校验不通过的数据。
- HBase作为Hadoop家族的数据库,提供了对数据的随机访问存储能力,不管是写入还是读取数据都比Hive这种OLAP系统要快,况且补录这种OLTP的事情本身就不应该在Hive上做。
至于在HBase做SQL查询,可以通过Impala/Hive上建立外部表即可执行SQL,也可以直接在HBase上利用Phoenix做SQL层,完成查询和校验。并且这种在HBase之上使用SQL引擎的做法可以直接使用HBase中的数据,不用重新导入数据,不会过分冗余。考虑到不在HBase层重复引入Hive,因此决定用Phoenix做SQL引擎,也就是现在的流程。HBase作为增量数据库,Hive作为全量数据库,整个过程分为两个部分,首先每一期的数据(增量数据)进HBase,通过Phoenix的UDF实现校验函数进行查询,在HBase中进行修改、补录;之后每期通过校验的数据load进Hive,Hive做为全量数据的存储,在Hive之上做分析,这里可以利用Impala加速Hive的查询,后续可以接入spark和R进行大数据分析。
目前的原始数据以txt的方式存储,将原始数据导入HBase首先要考虑的就是rowkey的问题。我们可以在HBase中建立之前的79张表,但是原始的表结构中经常有联合主键的存在,而HBase必须要保证每个rowkey的独特性,所以一种简单的做法是通过一个脚本拼接原来的联合主键得到HBase需要的rowkey。
以JYLS表为例,JYLS表的主键是hxjylsh这个字段,hxjylsh这个字段本身不重复的,如果某张表的主键为(pk1,pk2),为了保证rowkey唯一性,那么首先应该得到pk1_pk2作为HBase的基本rowkey。
假如直接利用hxjylsh这个字段作为HBase的rowkey,那么在导入数据的时候会非常缓慢。这里有两个原因,第一是没有对HBase的表做pre-split,这样初始情况下只有一个region,那么在执行MapReduce将数据导入HBase的过程时,只有一个Reducer,效率低下。另一个原因是这个hxjylsh字段是递增的,这就产生了HBase的热点region问题,导致每次导入的数据都在最新的region上,使得这个region需要不断的split,导致效率低下。
针对这两个问题,需要对rowkey做一些变换。首先是pre-split的问题,如果直接利用hxjylsh来进行pre-split①,因为hxjylsh的范围不好确定,所以split的点不好找,考虑到解决热点问题的一种常见方法是对rowkey加salt,salt是指hash值,也就是rowkey由hash(hxjylsh)+hxjylsh组成,hash的目的是为了使得每个region的数据分布均匀,避免热点,加速导入效率。并且利用hash结果16进制的前两个字母对HBase的表做pre-split非常方便,pre-split的目的是增加初始region的个数使得导入的reduce数量变多,效率提高。关于具体的导入可以利用HBase提供的importtsv工具,通过bulkload的方式将txt转换成HFile。具体的命令为
|
|
①pre-split:Hbase split有三种方式(pre-split、auto-split、forced-split),表示在建表的时候就预先设置生成多个region。
在table初始化的时候如果不配置的话,Hbase是不知道如何去split region的,因为Hbase不知道应该那个rowkey可以作为split的开始点。如果我们可以大概预测到rowkey的分布,我们可以使用pre-spliting来帮助我们提前split region。不过如果我们预测得不准确的话,还是可能导致某个region过热,被集中访问,不过还好我们还有auto-split。最好的办法就是首先预测split的切分点,做pre-split,然后后面让auto-split来处理后面的负载均衡。
Hbase自带了两种pre-split的算法,分别是HexStringSplit和UniformSplit,我们采用的是对rowkey做64进制的转换,得到结果截取前两位作为rowkey的前缀。
其中-Dimporttsv.separator指定文本文件的分隔符,-Dimporttsv.columns指定每行对应的HBase表中的字段,HBASE_ROW_KEY代表rowkey,剩下的以columnfamily:column的形式表示,-Dimporttsv.bulk.output表示输出目录给下面LoadIncrementalHFiles使用。现在一期交易流水可以在17分钟之内导入HBase。
值得注意的一点是增加region的个数是为了使得尽可能多的regionserver工作,增加并行度,类似于多线程,但并不是region越多效率越高,当每个regionserver满负荷时,region数量应该越少越好,对于一个regionserver来说,扫描多个小的region不如扫描一个大的region。虽然region多了,分布在多个regionserver上可以加速查询,但是考虑到regionserver的负载,对于一期的79张表每个regionserver上的region数量应该不超过1000。还有一个影响查询效率的因素是数据的本地化locality,一般locality越大查询越快,通常如果一张表通过pre-split之后控制每个region的大小不再进行split,基本可以保证每个regionserver上的数据就在对应的datanode上,也就是data locality为100%,这样查询效率是最高的,这也是pre-split的一个优点。
在将txt转换成HFile之后,通过HBase的LoadIncrementalHFiles将生成好的HFile移动到HBase的目录下,这个过程非常快。之后,就可以在HBase中查询到数据了。
例如执行
|
|
可以将bulk import生成的/user/co2y/output目录下的HFile文件载入进JYLS表中。
数据进入HBase之后,HBase原生只支持根据rowkey进行查询,并不能像SQL那样查询,这就需要接入SQL层引擎Phoenix。数据存在HBase中,在Phoenix中建表,通过SQL就可以查询HBase中的表。对于1亿2千万的一个月的JYLS,在没有缓存的情况下100s左右可以扫描完,也就是可以完成对任意字段的过滤,如果有缓存20s即可完成。HBase中的表是为了做校验,校验可以将相关规则通过Phoenix的UDF封装成一个函数,使用和Hive的基本一样,都是接在where子句后面做一个查询,每个校验其实就是对全表的一次扫描,只不过是对某个字段的一种过滤。上面提到data locality对查询是有影响的,理想情况下,regionserver和datanode在一个节点上,然后regionserver管理的region刚好也在这个datanode上,那么效率是最高的。经过测试,当数据分布被打乱时,扫描一个月的JYLS表,耗时可能从90s到200s不等,因此在pre-split保证了data locality的情况下,尽量不要打乱数据。这里尤其要提到的是不要直接对hadoop的datanode数据分布做balance。即使HBase的data locality被打乱了,在HBase发生compaction的时候,会恢复data locality。所以在Hadoop之上运行HBase时,最好由HBase来进行balance。
对于JYLS这种大表且是每月校验的,可以按目前的方式进行。按照之前的思路,对于小表,应该适当减小region大小来增加region个数,然后对于需要按天分析的数据应该在rowkey上拼接采集日期cjrq,也就是rowkey=cjrq+hash+pk,这样也可以按cjrq范围检索。
最后通过Hive在HBase中建外部表,然后再建内部表,把外部表的数据(HBase中的一期校验通过的数据)load到Hive中,做全量保存。整个过程如下图所示。
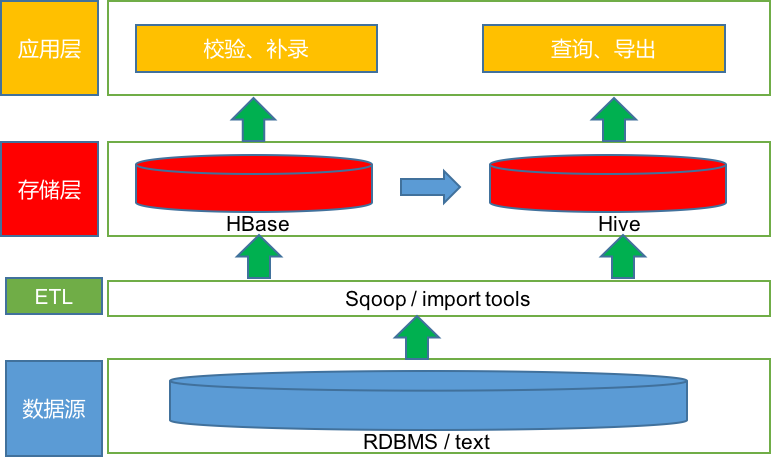
总结一下这个方案,利用HBase做OLTP,再HBase之上利用Phoenix作为SQL引擎,既可以提供类似于Hive的查询,也可以提供毫秒级的修改。
后续问题
现在基本完成了整个流程,但是用到的大部分还是Hadoop/HBase/Phoenix/Hive的默认配置,这其中还有很多地方可以进行优化。总结如下
- 关于环境,CDH是个不错的发行版,可以集成所有的组件,可能只需要额外安装Phoenix
- 目前机器内存并没有用完,可以增加regionserver和master的内存。此外可以增加namenode和hmaster的个数保证集群的稳定性
- 分区的问题,现在的pre-split和rowkey设计可能可以优化,Hive可以指定列进行分区,HBase只能利用rowkey和region来优化做范围扫描,是否存在第三种分区方式?
- 虽然用bulkload代替了put,但是对于HBase的写入可以有进一步优化,比如关闭WAL
- 关于查询,也就是读HBase,可以从优化SQL,减少通信流量,缓存,利用服务端的coprocessor等方面来考虑
- region大小,分割和合并;以及memstore的flash,文件的compact的阈值的设定。
- 如果HBase服务器压力过大,可以将zookeeper和regionserver分离
- 压缩数据没有开启,压缩之后表的大小减小和减小网络传输时间,但是查询时解压缩可能会慢。