本文主要对当前主流的大数据处理平台做一个简介,包括它们的发展史、整体结构、相互之间关系和使用场景,属于科普文章。
背景
2003年Google发布了Google File System,之后的2004年又发布了MapReduce。受到启发的Doug Cutting等人于2006年开发出Hadoop,同年发表的还有Bigtable(HBase前身)。2008年Hadoop成为Apache顶级项目。早期的Hadoop主要由两个核心组件构成:HDFS和MapReduce编程模型。随着Hadoop的发展,一些围绕在Hadoop周围的开源项目逐步诞生,主要是ZooKeeper、Hive、Pig、HBase、Storm、Kafka、Flume、Sqoop、Oozie、Mahout等,它们共同形成了Hadoop生态圈。2012年,Hadoop V2发布,其中最重要的变化是在Hadoop核心组件中增加了YARN,并把MapReduce作为Hadoop的计算框架。YARN的出现是为了把计算框架与资源管理彻底分离开,解决了Hadoop V1由此带来的扩展性差、单点故障和不能同时支持多种计算框架的问题。YARN对标的是资源调度器,例如Mesos,Borg等。
至此,Hadoop生态圈已经成熟(以下说的Hadoop统一指Hadoop V2),越来越多的处理平台可以统一进Hadoop家族,当今主流的处理平台主要包括Hadoop,HBase,Hive,Storm,Spark,Flink等。
平台
Hadoop
基本结构
Hadoop的核心包括HDFS和YARN两个部分。HDFS负责底层存储,提供容错,它分为NameNode和DataNode,NameNode上保存着HDFS的名字空间,任何对文件系统元数据产生修改的操作都会作用于NameNode上。DataNode将HDFS数据以块为单位(默认128M),以文件的形式存储在本地的文件系统中,默认是3备份。因为NameNode保存着所有的元数据,非常重要,所以通常需要一个Secondary NameNode作为替代,并且配置NameNode对它的元数据做持久化备份。
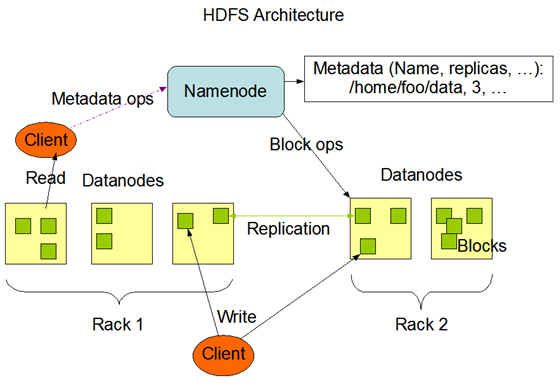
YARN负责资源的调度和管理,许多开源项目包括下文提到的Storm,Spark和Flink都可以跑在YARN上。将这些框架部署到YARN上可以弹性的分配整个Hadoop集群的计算资源,共享底层存储,在一个统一的平台上完成调度。
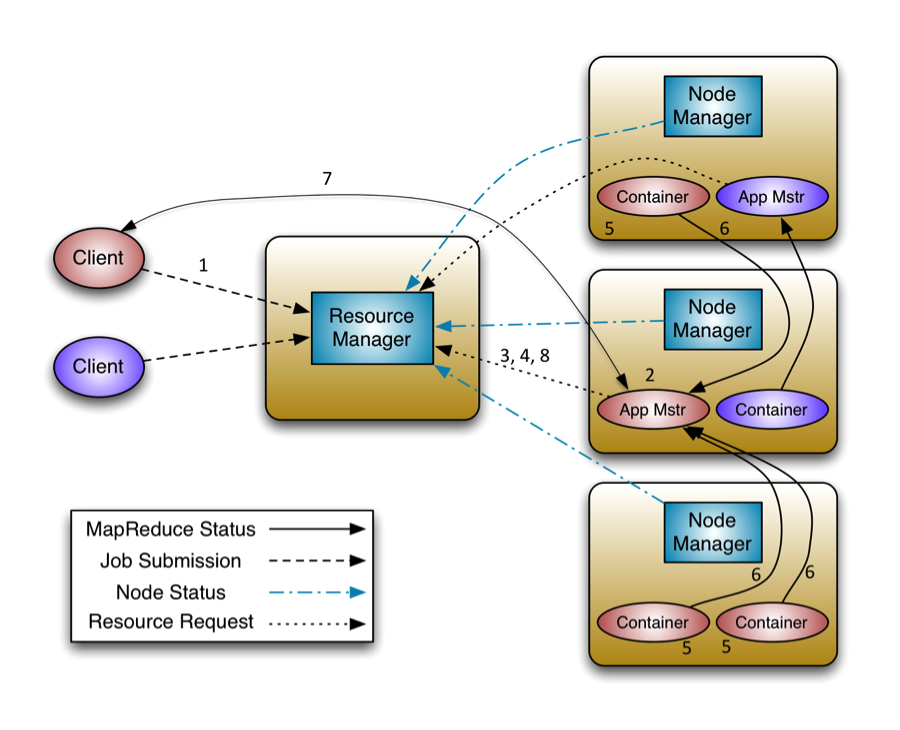
YARN包括一个全局的资源管理器ResourceManager,每个节点上的NodeManager和每个应用程序特有的ApplicationMaster。其中ResourceManager负责对各个NodeManager上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响。ApplicationMaster负责单个应用程序的管理。整体结构图如下。
运算模型
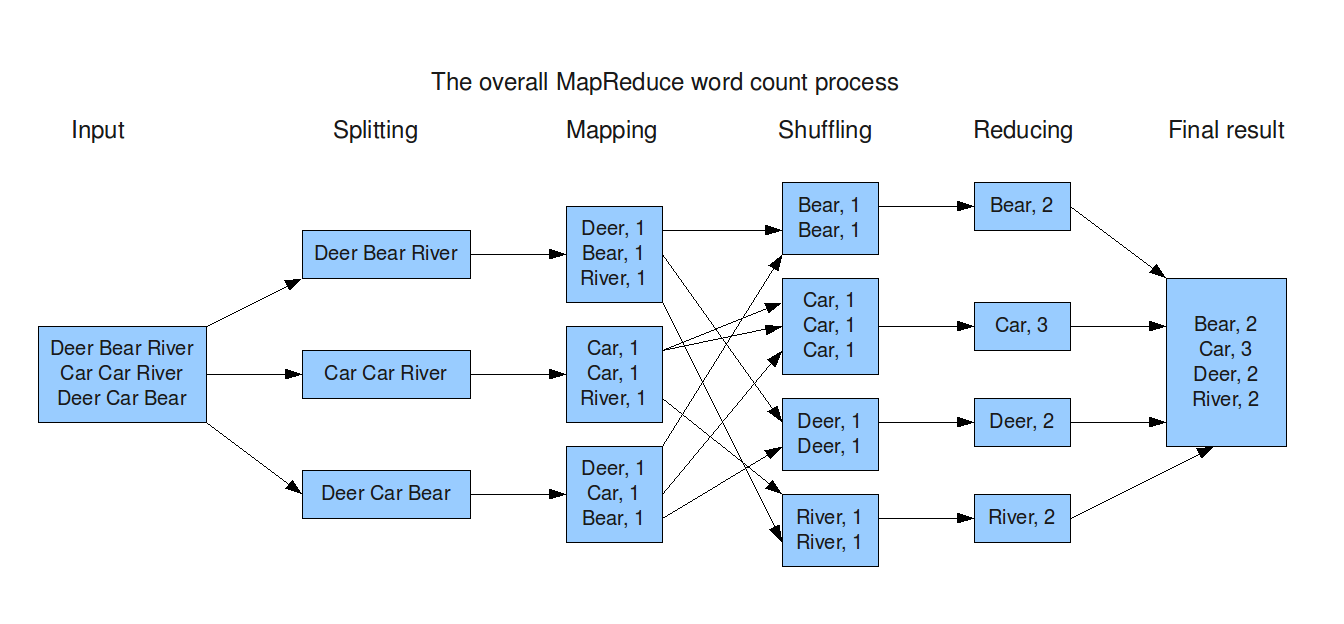
Hadoop上内置的编程模型是MapReduce,MapReduce作为YARN内置的一种计算框架和编程模型可以执行用户提交在Hadoop集群中的程序。它主要由map(),shuffle(),reduce()几个算子组成。这种简单的编程模型给开发者极大的便利,但是它也有缺点,例如Map之后总是要Reduce,Reduce的结果要存HDFS。
代码示例
以WordCount为例,我们需要实现map()和reduce()两个函数,
|
|
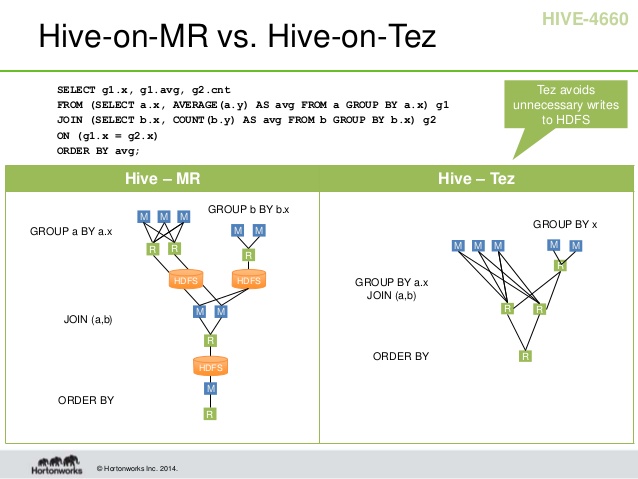
为了减少中间结果写入磁盘的次数,增强MapReduce的表达能力,改善固有的Map-Reduce—Map-Reduce的编程模式,Hortonworks提出了Tez。Tez是对MapReduce的一层封装,它可以兼容原先的MapReduce,通常也运行在YARN之上。它提供了一组API可以将原先多个有依赖的MapReduce作业转换为一个DAG作业从而大幅提升性能,例如它可以提供Map-Map-Reduce这样的结构。此外Tez通过管理session,避免每次启动MapReduce任务的开销。这两点使得Tez的运行效率通常要高于MapReduce。下面是MapReduce和Tez的一个对比。
使用场景
正如上面介绍到的,Hadoop包括HDFS和YARN两个部分,其中内置了MapReduce的ApplicationMaster。所以Hadoop的主要场景是为其它组件提供底层存储(HDFS)和资源调度(YARN),而其它组件想要在上面运行需要实现对应的ApplicationMaster。当然,Hadoop也可以跑用户编写的MapReduce程序。
HBase
简介
HBase通常搭建在Hadoop的HDFS之上。HDFS是一个只读的追加型文件系统,它的设计目标是为了存储和分析大量的数据,通常是一次写入多次读取的数据,因此直接修改数据的block代价较高。而HBase的出现正是弥补了Hadoop随机存取的能力。HBase是一个列族型的非关系数据库,里面存的是键值对。HBase是一个LSM树型存储结构,这种设计提高了数据插入的性能,并且在compaction的时候清除被删除的数据,契合HDFS的设计。另外,HBase为了快速读取数据,它的文件块要比HDFS的块小的多。HBase的存储文件称为HFile,HFile是存放在HDFS上的,利用HDFS的容错和可靠性支持。
HBase的逻辑结构如下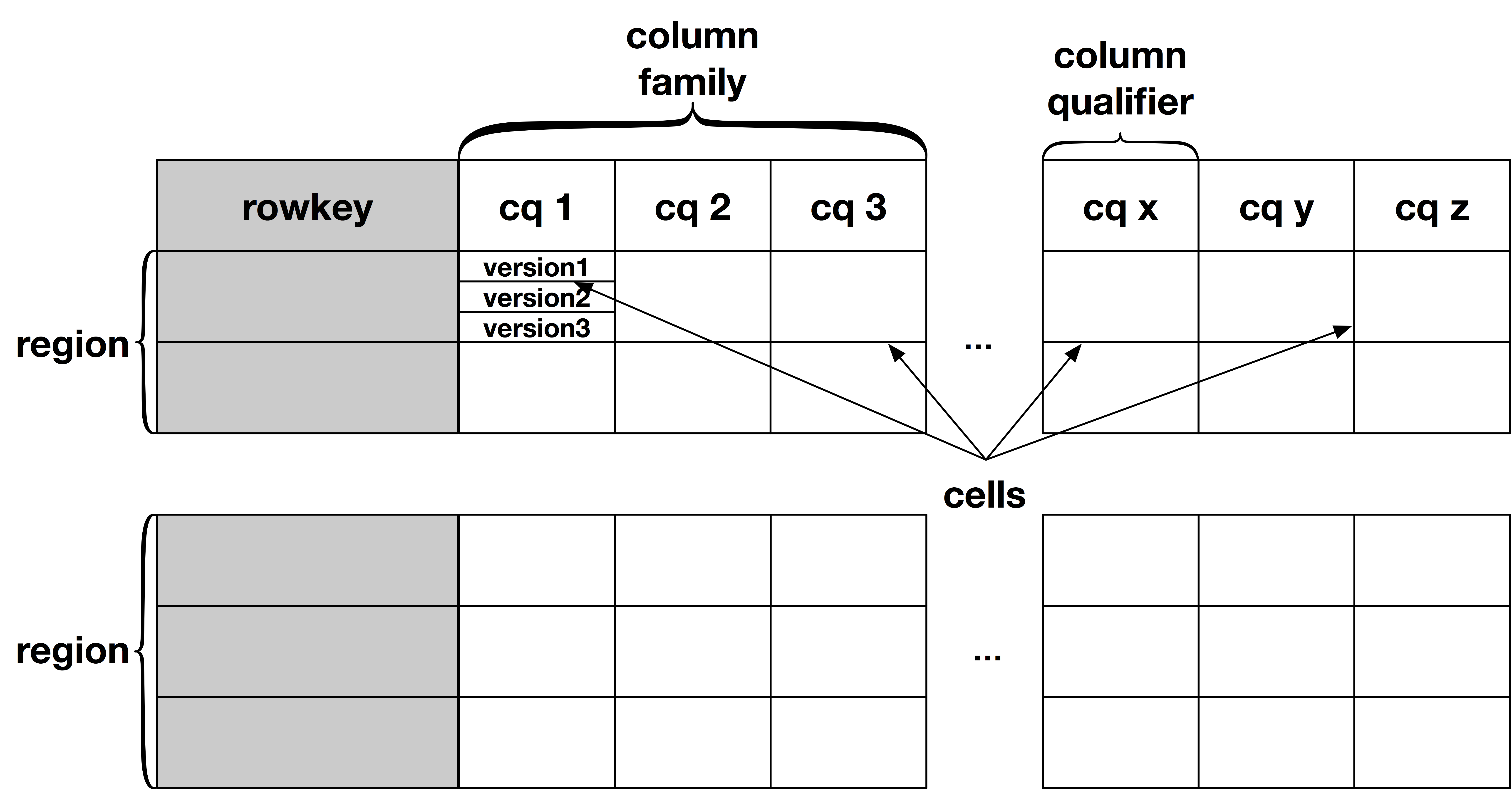
HBase的物理结构如下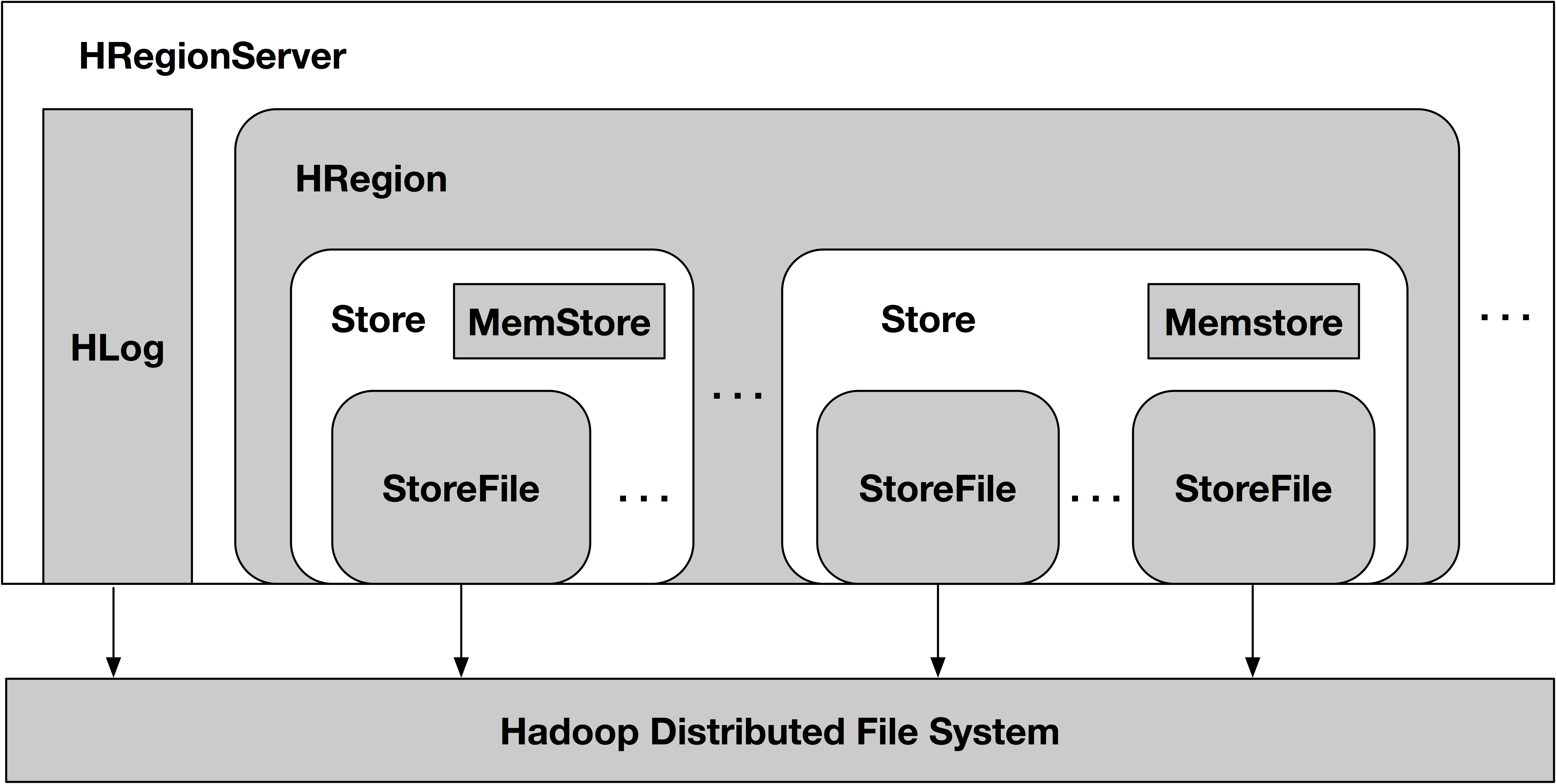
对于开发人员,HBase提供了一组API供客户端来进行CRUD,并且提供了coprocessor的接口,类似于关系型数据库中的触发器和存储过程。
从HBase的表结构可以看出,它只能够根据rowkey进行范围读取,或者进行全表扫描。像索引,join等SQL特性,HBase本身不提供,需要其它的组件提供这些支持。Phoenix作为HBase上的一个SQL层被广泛使用。另外HBase可以和下面提到的Hive集成,以及其它通过Hive获得元数据的SQL引擎配合使用,例如Spark SQL等都可以以SQL的形式来操作HBase上的数据。
代码示例
HBase提供了一组API,主要是Put(),Get(),Scan()。
|
|
适用场景
HBase建立在HDFS之上,是一个列族型的Key-Value数据库,提供键值存储,支持随机查询和修改,支持范围查询,面向OLTP,提供行级的一致性。但是因为HBase查询单一,所以除非业务完全适合HBase模型,一般需要和Phoenix或者其它OLAP工具结合使用。
Hive
简介
Hive的出现是为了解决数据分析人员需要编写大量MapReduce任务的问题。它能够将SQL翻译成对应的MapReduce job。Hive提供了CLI,JDBC,Web等多种客户端接口。Hive既可以操作HDFS上的数据,也可以操作HBase里的数据,除了顺序扫描,Hive都是以MapReduce的方式去进行数据分析和处理的。
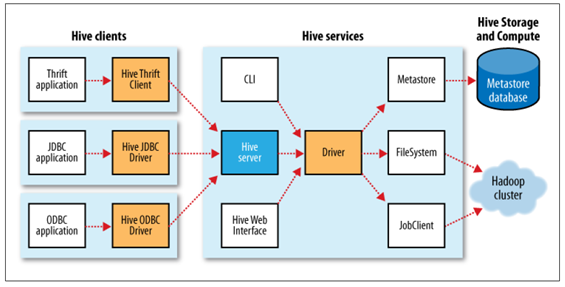
值得一提的是,虽然Hive内置的计算引擎是MapReduce,但它也可以和上面提到的Tez配合使用,Tez能够运行任意MR任务且不需要改动。此外Hive可以为其他SQL on Hadoop方案提供元数据,例如后面提到的Spark SQL,以及Impala等,从这个角度来看,Hive是一个中间者的角色,负责提供元数据,具体的计算由其它引擎完成。
代码示例
Hive可以通过JDBC的方式操作数据。
|
|
使用场景
Hive在HDFS之上提供数据分析能力,以SQL的方式操作数据,免去数据分析人员频繁编写简单MapReduce程序的工作。通常适用于OLAP场景,如大批量数据的查询和分析,ETL,生成报表等。Hive的SQL兼容SQL 92,用户可以通过JDBC的方式连接Hive,操作数据。
此外,Hive为Spark SQL、Flink等其它SQL on Hadoop工具提供元数据。
Storm
简介
不同于Hive这种先把数据放入HDFS再进行处理的批处理方式,Storm提供了实时的流式处理,两者互补分别解决不同场景下的问题。将Storm部署到Hadoop之上,可以和其它程序(如MapReduce)共享整个集群的资源,通过YARN统一管理。
Storm实现了一个数据流(data flow)的模型,在这个模型中数据持续不断地流经一个由很多转换实体构成的网络。一个数据流的抽象叫做流(stream),流是无限的元组(Tuple)序列。元组就像一个可以表示标准数据类型(例如int,float和byte数组)和用户自定义类型(需要额外序列化代码的)的数据结构。Storm拓扑图如下。
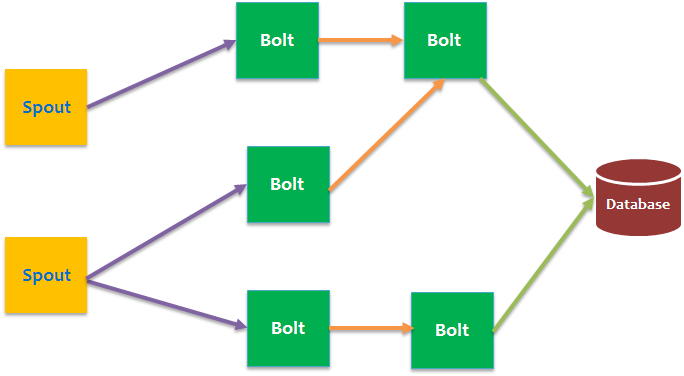
Storm中的流的来源叫Spout,通常Spout从外部数据源读取数据,例如kafka,然后吐到拓扑里。在拓扑中所有的计算逻辑都是在Bolt中实现的。一个Bolt可以处理任意数量的输入流,产生任意数量新的输出流。Bolt可以做函数处理,过滤,流的合并,聚合,存储到数据库等操作。
代码示例
以下是流式处理WordCount。
|
|
使用场景
强实时性,流式处理。如实时分析日志和入库。
Spark
简介
Spark官方定义是一个用于大规模数据处理的快速和通用引擎。它和Hadoop的结合主要表现在它可以利用YARN进行资源调度和管理,利用HDFS作为持久化存储,当然这两者都是可以替换的。Spark已经逐渐发展为一个完整的数据平台,上面提供了多种处理方式,包括Spark SQL,Spark Streaming,图计算,机器学习库等。
Spark集群也是一个主从式架构。
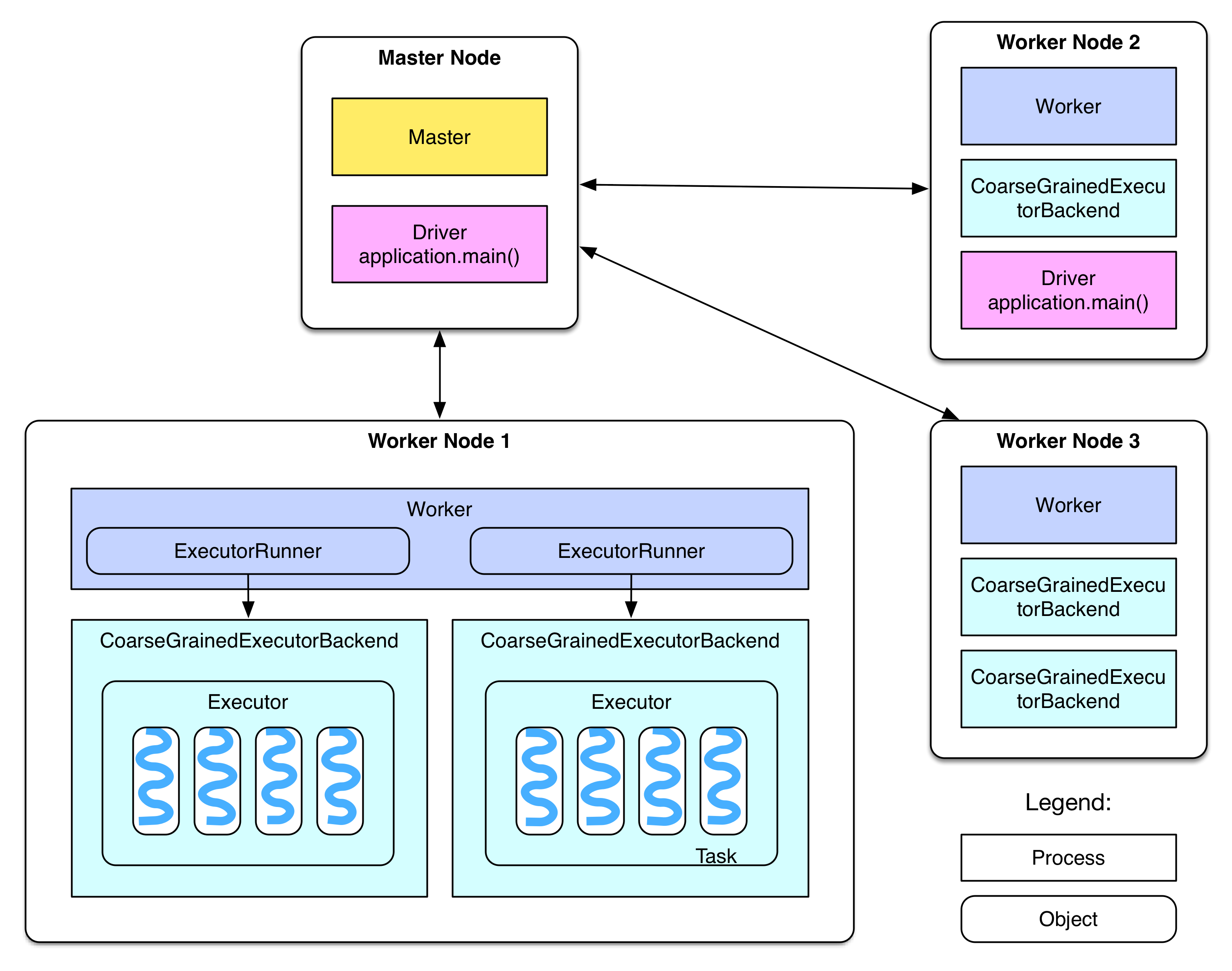
Spark将数据抽象成RDD(是弹性分布式数据集),它是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。RDD有两类操作Transformation和Action,前者只记录转换规则,后者触发真正的操作。因此可以通过Transformation的“世系”机制来对RDD进行恢复做容错处理。
RDD的一个Action对应一个job。整个job会产生哪些RDD由transformation来决定,一个RDD包含多个partition,每个分区对应Executor中的一个task线程。RDD之间有NarrowDependency和ShuffleDependency(wide)两种,只有前后两个RDD的partition个数及partitioner都一样才会出现NarrowDependency,这也是划分一个job中stage位置的判断依据。
Spark中的API都是建立在RDD之上的,包括处理二维表的DataFrame和处理流的DStream。
代码示例
Spark在RDD的基础上提供了DataSet,DataFrame和DStream,可以方便的应对各种处理需求。
|
|
使用场景
完整的处理引擎,可以和Hadoop,Hive,HBase配合使用。从数据处理逻辑的角度来看,MapReduce相当于Spark中的map()+reduceByKey(),此外Spark还提供了更加丰富的算子可以用于流处理和SQL处理。由于RDD的特性,Spark不适合细粒度状态更新的应用,例如Spark Streaming是通过微批处理的方式来进行流式计算的。
Flink
简介
Flink和Hadoop的结合也是通过HDFS和YARN。默认情况下Flink的Standalone有自己的JobManager和TaskManager。甚至于在YARN中,Flink也承担了一部分任务管理的功能。

要介绍Flink,需要把它和Spark对比其他看。早期的Flink是一个流式处理平台,随着发展,它和Spark越来越像。Flink最大的特点是把所有的抽象都建立在流之上,Spark中的流处理是在一批RDD之上,把流处理看做是特殊的批处理,而Flink则是把批处理看成Streaming的特殊例子,差异如下:
其一,在实时计算问题上,Flink提供了基于每个事件的流式处理机制,所以它可以被认为是一个真正意义上的流式计算,类似于Storm的计算模型。而对于Spark来说,不是基于事件粒度的,而是用小批量来模拟流式,也就是多个事件的集合。所以,Spark被认为是一个接近实时的处理系统。虽然,大部分应用实时是可以接受的,但对于很多应用需要基于事件级别的流式计算,因而会选择Storm而不是Spark Streaming,现在Flink也许是一个不错的选择。
代码示例
还是以WordCount为例。
|
|
使用场景
Flink的发展路线同Spark一样,也是往完整的生态系统发展。目前Flink上的组件也支持关系型表(SQL),图处理,机器学习库,另外它支持实时响应的流式处理。但是Flink整体成熟度不如Spark。
平台小结
自Hadoop V2提供批处理MR编程模型以来,为了减轻数据处理人员编写MapReduce任务的麻烦,Hive出现了,它将人们熟悉的SQL翻译成MapReduce job,使得数据分析人员可以通过SQL来分析数据。为了解决Hive/Hadoop文件只读的问题,HBase作为一个NoSQL数据库提供了快速地随机读取、修改数据的能力,并且提供OLTP,保证行级的事务性,结合Tephra可以获得完整的ACID,并且可以和Hive以及其它SQL on Hadoop工具配合使用。为了解决固有MapReduce编程模型的缺点,以及减少迭代式任务中间数据存取硬盘的开销,Tez、Impala、Spark SQL等SQL on Hadoop组件出现了,它们利用Hive提供的元数据,优化原先的MR固定模型,提供更加细粒度的算子,以DAG的形式运行整个job,因此能够更快的获得SQL结果。为了进行实时处理,Storm,Spark Streaming,Flink出现了。最后,为了统一批处理和流处理,Spark和Flink作为主流的两个平台正在往通用计算引擎方向发展。而在这之上,还有统一Spark和Flink等平台API的Apache Beam项目。
目前的企业架构上通常是把Hadoop、Hive、HBase、Spark和Flink结合使用。为了方便搭建这些平台,在社区版本的基础上,还有一些Hadoop厂商提供企业发行版,例如CDH,HDP等。这些企业Hadoop发行版将上述提到的开源组件整合到了一个平台之上(还有Hadoop生态圈的其它组件)并做了一些定制,并且提供了安装、部署、监控的工具,大大方便了平台运维人员。
数据处理库
Apache Mahout
Mahout提供了适用于Hadoop的机器学习和数据挖掘的分布式计算框架。早期的Mahout基于MapReduce,但是MapReduce本身不适用与迭代式计算,近年来随着Mahout Samsara的发展,现在的Mahout可以和Spark、H2O、Flink等多种计算引擎结合使用,原先MapReduce的计算方式也已经被抛弃了。新生的Samsara提供了Scala和Shell的接口,供用户使用。
Mahout提供了许多现有的算法库,包括但不限于以下这些:
- 协同过滤
- 基于用户
- 基于物品
- ALS、SVD矩阵分解等
- 分类
- 逻辑回归
- 贝叶斯
- 隐式马尔科夫等
- 聚类
- K-Means
- 谱聚类等
- 降维
- SVD
- PCA等
- 主题模型
- LDA
- 杂项
Mahout的主要应用场景是推荐引擎,许多商业用例可以在这里看到。
Mahout为数据分析人员,解决了大数据的门槛;为算法工程师,提供基础的算法库;为Hadoop开发人员,提供了数据建模的标准;为运维人员,打通了和Hadoop连接。
Spark MLlib
MLlib是Spark中提供机器学习的库,原先建立在RDD之上,现在的ML也提供了DataFrame之上的API。MLlib也实现了许多经典的算法,并且提供了Scala、Java、Python等接口,具体的算法包括但不限于:
- 基本统计
- 概况统计
- 相关性
- 分层抽样
- 假设检验
- 随机数生成
- 分类和回归
- 线性模型(SVM,线性回归,逻辑回归)
- 贝叶斯
- 决策树
- 随机森林等
- 协同过滤
- ALS
- 聚类
- KMeans
- 降维
- PCA
- SVD
- 优化部分
- 随机梯度下降等
使用方式
要想使用这些机器学习库其实很方便,只要提供符合InputFormat的数据集,就可以调用对应的算法。下面是两个例子:
|
|
|
|
使用场景
许多商业场景都可以使用上述的经典算法,例如市场营销和风险管理等。
- 营销响应分析建模(逻辑回归,决策树)
- 净提升度分析建模(关联规则)
- 客户保有分析建模(卡普兰梅尔分析,神经网络)
- 购物篮分析(关联分析Apriori)
- 自动推荐系统(协同过滤推荐,基于内容推荐,基于人口统计推荐,基于知识推荐,组合推荐,关联规则)
- 客户细分(聚类)
- 流失预测(逻辑回归)
- 客户信用风险评分(SVM,决策树,神经网络)
- 市场风险评分建模(逻辑回归和决策树)
- 运营风险评分建模(SVM)
- 欺诈检测(决策树,聚类,社交网络)